
TurboQuant
New LLM compression algorithm by Google
About TurboQuant
TurboQuant, developed by Google, introduces an innovative set of LLM compression algorithms designed to significantly reduce the size of large language models and vector search engines. By leveraging advanced, theoretically grounded quantization techniques, TurboQuant enables organizations to deploy massive neural networks more efficiently, reducing storage and computational costs without sacrificing performance. This tool is particularly beneficial for AI developers, researchers, and enterprises aiming to optimize their large-scale language models for deployment in resource-constrained environments. Its unique approach to compression allows for maintaining high accuracy while drastically decreasing model size, making it a game-changer for scaling AI solutions.
Screenshots
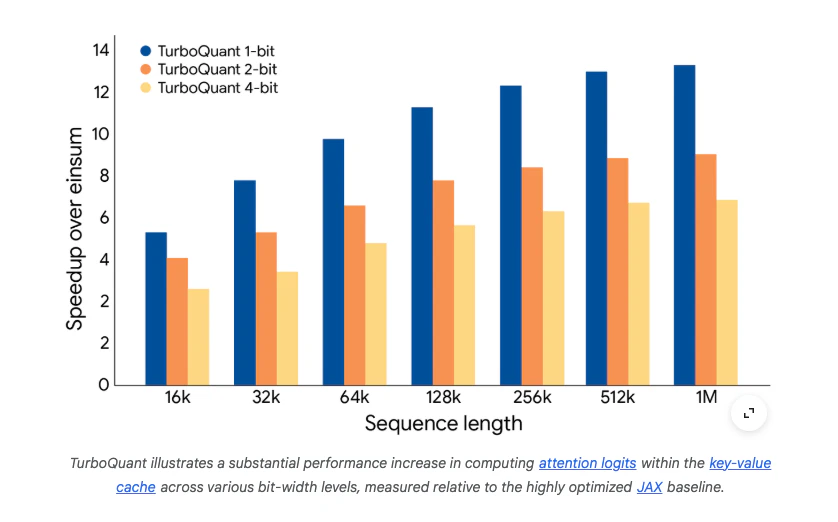
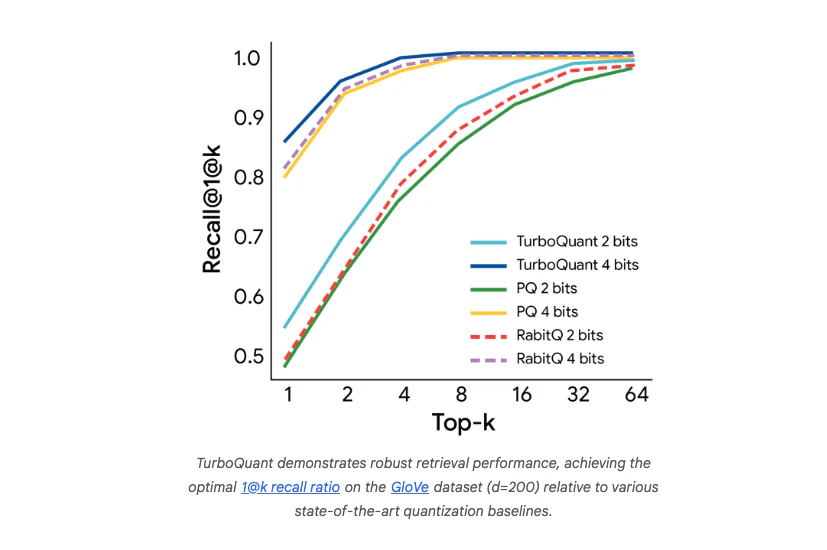
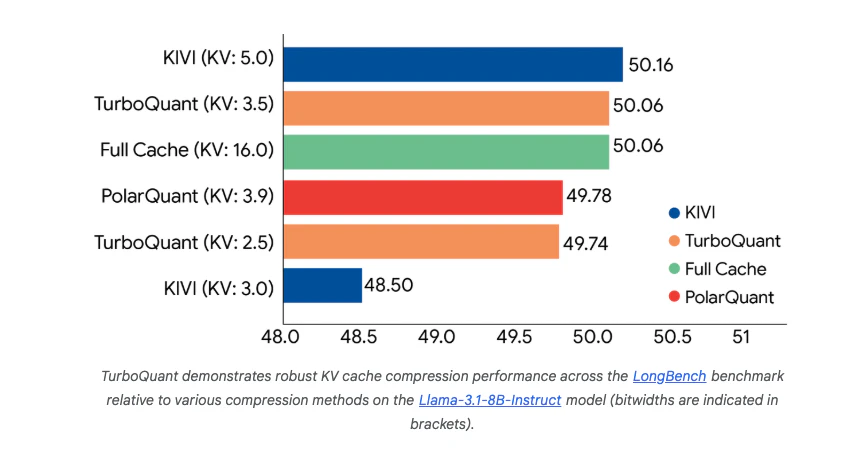

Pros
- ✓Enables massive compression of large language models and vector search engines
- ✓Theoretically grounded algorithms ensure minimal performance loss
- ✓Reduces storage and computational costs significantly
- ✓Ideal for deployment in resource-constrained environments
- ✓Backed by Google's expertise in AI and hardware efficiency
Cons
- ✗May require technical expertise to implement effectively
- ✗Details on pricing and availability are limited
- ✗Potential compatibility issues with existing AI frameworks
Use Cases
Pricing
Uncertain, but likely follows a B2B enterprise SaaS model with customized pricing based on compression needs and deployment scale. Free trials or limited access may be available for testing.
Quick Info
Topics
Alternatives
Similar Tools in AI Assistants
Embed Badge
Add this badge to your website to show that TurboQuant is featured on Visalytica.
<a href="https://www.visalytica.com/tool/turboquant" target="_blank" rel="noopener noreferrer" style="display:inline-flex;align-items:center;gap:6px;padding:6px 14px;background:#7c3aed;color:#fff;border-radius:8px;font-family:-apple-system,system-ui,sans-serif;font-size:13px;font-weight:600;text-decoration:none;transition:background .2s" onmouseover="this.style.background='#6d28d9'" onmouseout="this.style.background='#7c3aed'"><svg width="14" height="14" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2.5" stroke-linecap="round" stroke-linejoin="round"><path d="M12 20V10"/><path d="M18 20V4"/><path d="M6 20v-4"/></svg>Featured on Visalytica</a>