
SemanticGuard
Cuts your LLM API costs by 40-70%. One line of code.
About SemanticGuard
SemanticGuard is an innovative caching solution designed for businesses leveraging large language models (LLMs) like OpenAI, Anthropic, or Google. It intelligently identifies repeated prompts and questions within your application's API calls, significantly reducing redundant requests. By sitting seamlessly between your app and the LLM providers, SemanticGuard offers lightning-fast cache hits in under 50 milliseconds, enabling companies to cut their API costs by an impressive 40-70%. Its one-line installation makes integration straightforward, and the Shadow Mode feature allows developers to preview potential savings without risking live errors. Every cached response is validated by your own AI, ensuring the accuracy and reliability of served answers. This makes SemanticGuard ideal for organizations aiming to optimize operational costs while maintaining high-quality AI outputs.
Screenshots
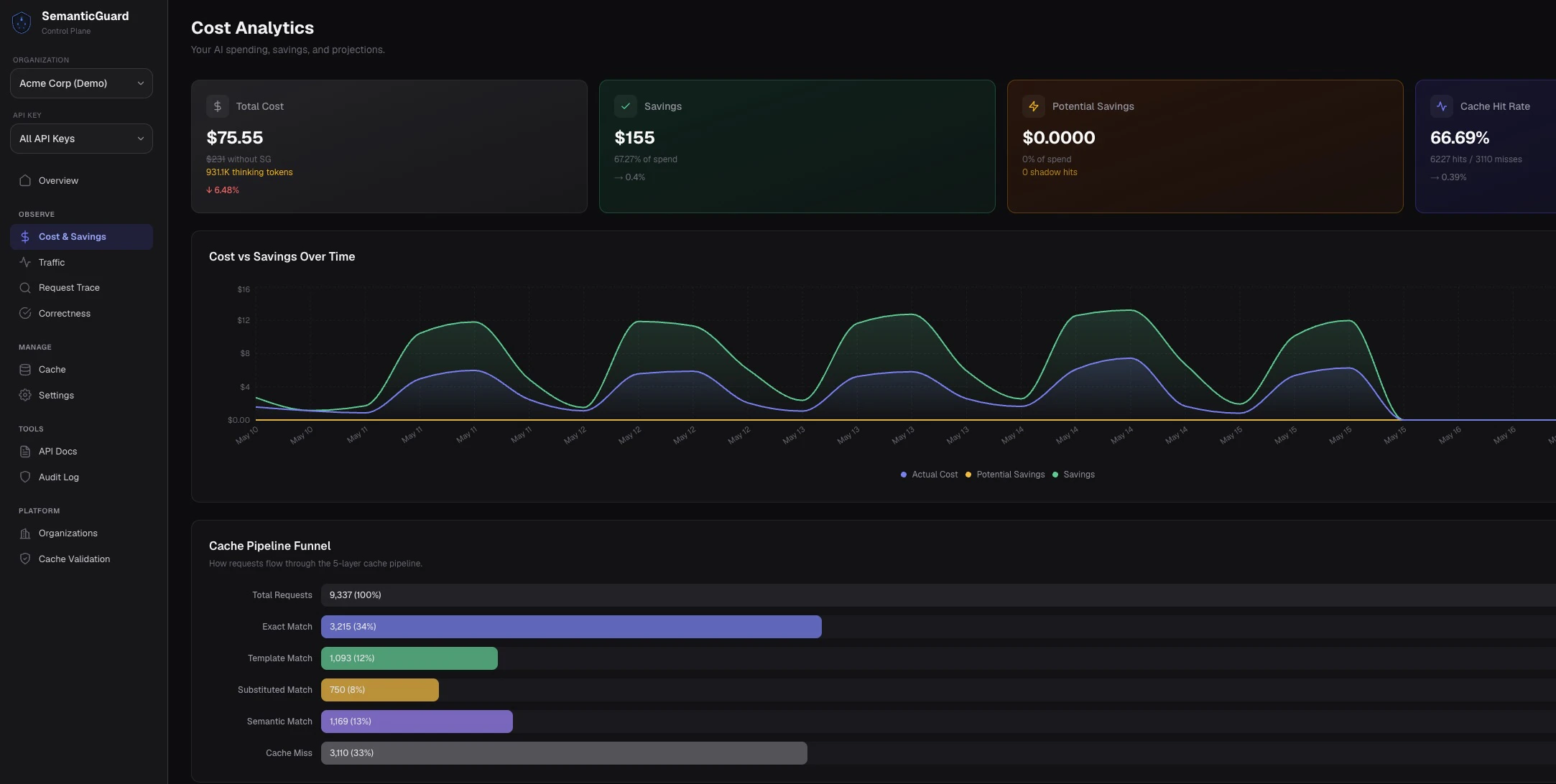
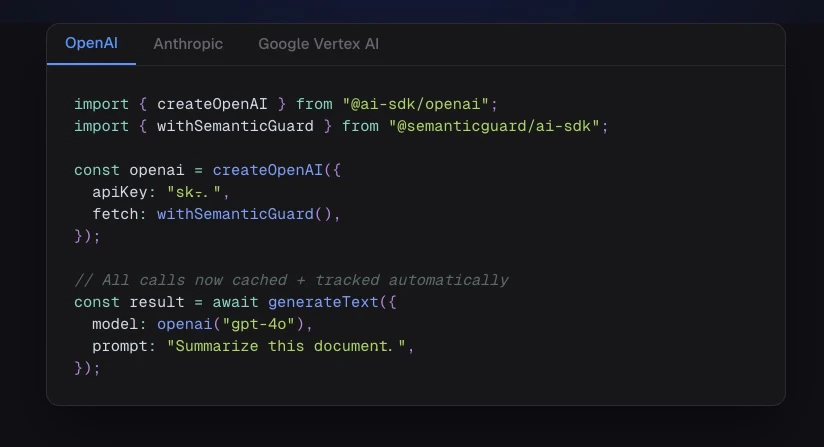
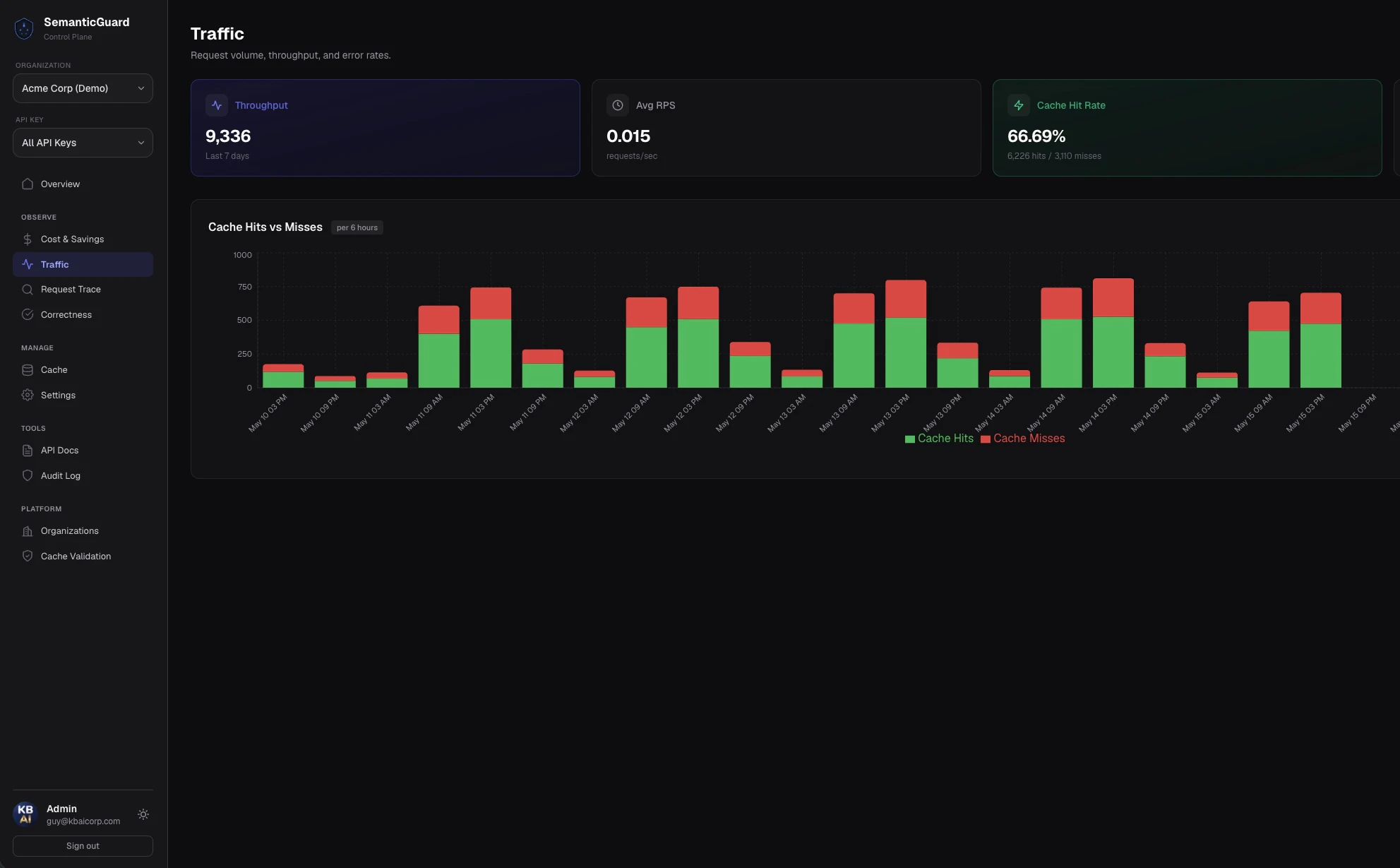
Pros
- ✓Drastically reduces LLM API costs by up to 70%
- ✓Simple one-line integration for quick deployment
- ✓Fast cache retrieval (<50ms) enhances user experience
- ✓Shadow Mode allows safe testing of savings before activation
- ✓Ensures response accuracy with internal validation
Cons
- ✗Primarily effective in environments with high prompt repetition
- ✗Requires setup of internal AI validation for responses
- ✗Limited information on long-term scalability and support
Use Cases
Pricing
Likely follows a freemium model with a free tier for basic use, and paid plans based on the volume of cached requests and API calls, but specific pricing details are not publicly disclosed.
Quick Info
Topics
Alternatives
Similar Tools in Developer Tools
Embed Badge
Add this badge to your website to show that SemanticGuard is featured on Visalytica.
<a href="https://www.visalytica.com/tool/semanticguard" target="_blank" rel="noopener noreferrer" style="display:inline-flex;align-items:center;gap:6px;padding:6px 14px;background:#7c3aed;color:#fff;border-radius:8px;font-family:-apple-system,system-ui,sans-serif;font-size:13px;font-weight:600;text-decoration:none;transition:background .2s" onmouseover="this.style.background='#6d28d9'" onmouseout="this.style.background='#7c3aed'"><svg width="14" height="14" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2.5" stroke-linecap="round" stroke-linejoin="round"><path d="M12 20V10"/><path d="M18 20V4"/><path d="M6 20v-4"/></svg>Featured on Visalytica</a>