
Mercury 2
Fastest reasoning LLM built for instant production AI
About Mercury 2
Mercury 2 is an innovative AI language model designed for real-time reasoning tasks, tailored for developers and AI practitioners who need ultra-fast, high-quality language generation. Unlike traditional sequential decoding models, Mercury 2 employs a parallel refinement approach, enabling it to generate tokens simultaneously and achieve an impressive rate of over 1,000 tokens per second. This breakthrough makes it particularly suitable for latency-sensitive applications such as real-time agents, conversational AI, and complex reasoning tasks, where speed and accuracy are paramount. Its unique reasoning diffusion architecture sets it apart from conventional LLMs, offering a blend of reasoning depth and rapid response times that are ideal for production environments demanding both performance and precision.
Screenshots

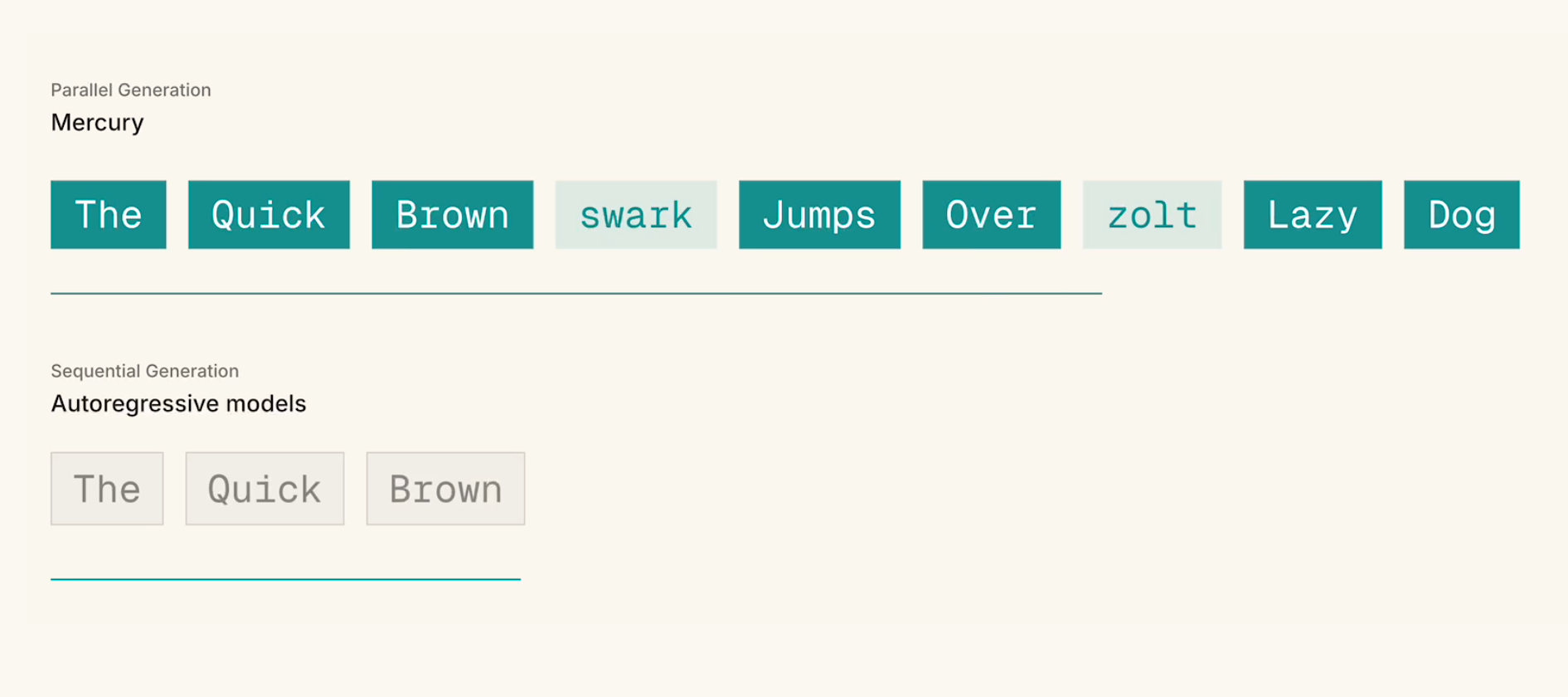

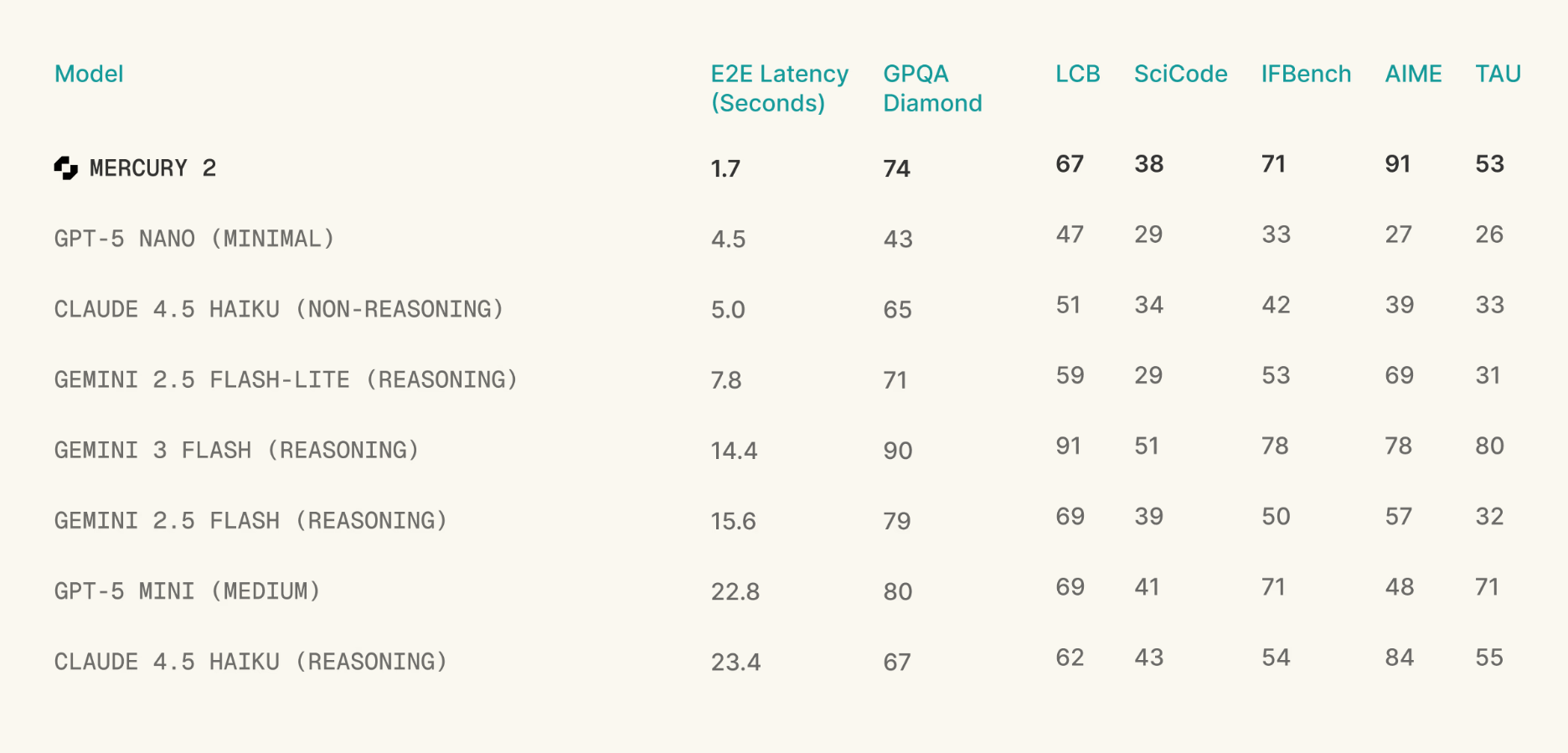
Pros
- ✓Exceptional speed with over 1,000 tokens/sec generation
- ✓Parallel token refinement enhances reasoning quality and reduces latency
- ✓Optimized for production use with reasoning-grade accuracy
- ✓Ideal for latency-sensitive AI applications and agent loops
- ✓First of its kind as a reasoning diffusion LLM
Cons
- ✗Relatively new technology, may have limited community support initially
- ✗Potentially higher resource requirements due to parallel processing
- ✗Limited information on pricing and deployment options
Use Cases
Pricing
Likely employs a pay-as-you-go or subscription model tailored for enterprise and development teams, with possible tiered plans based on usage volume and latency requirements. Exact pricing details are not publicly specified.
Quick Info
Topics
Alternatives
Similar Tools in AI Assistants
Embed Badge
Add this badge to your website to show that Mercury 2 is featured on Visalytica.
<a href="https://www.visalytica.com/tool/mercury-2" target="_blank" rel="noopener noreferrer" style="display:inline-flex;align-items:center;gap:6px;padding:6px 14px;background:#7c3aed;color:#fff;border-radius:8px;font-family:-apple-system,system-ui,sans-serif;font-size:13px;font-weight:600;text-decoration:none;transition:background .2s" onmouseover="this.style.background='#6d28d9'" onmouseout="this.style.background='#7c3aed'"><svg width="14" height="14" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2.5" stroke-linecap="round" stroke-linejoin="round"><path d="M12 20V10"/><path d="M18 20V4"/><path d="M6 20v-4"/></svg>Featured on Visalytica</a>